目录
一、ThreadPool 线程池
1、参数说明
2、拒绝策略
3、线程池种类
(1)newCachedThreadPool(常用)
(2)newFixedThreadPool(常用)
(3)newSingleThreadExecutor(常用)
(4)newScheduleThreadPool(了解)
(5)newWorkStealingPool
4、线程池入门案例
5、注意事项
二、Fork/Join
1、框架简介
2、案例
一、ThreadPool 线程池
1、参数说明
可看这篇文章
2、拒绝策略
CallerRunsPolicy
: 当触发拒绝策略,只要线程池没有关闭的话,则使用调用线程直接运行任务。一般并发比较小,性能要求不高,不允许失败。但是,由于调用者自己运行任务,如果任务提交速度过快,可能导致程序阻塞,性能效率上必然的损失较大
AbortPolicy
: 丢弃任务,并抛出拒绝执行 RejectedExecutionException 异常信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行。
DiscardPolicy
: 直接丢弃,其他啥都没有
DiscardOldestPolicy
: 当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞队列 workQueue 中最老的一个任务,并将新任务加入

3、线程池种类
(1)newCachedThreadPool(常用)
作用
:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.
特点
:
•
线程池中数量没有固定,可达到最大值(Interger. MAX_VALUE)
•
线程池中的线程可进行缓存重复利用和回收(回收默认时间为 1 分钟)
•
当线程池中,没有可用线程,会重新创建一个线程
创建:
java"> /**
* 可缓存线程池
*
* @return
*/
public static ExecutorService newCachedThreadPool() {
/**
* corePoolSize 线程池的核心线程数
* maximumPoolSize 能容纳的最大线程数
* keepAliveTime 空闲线程存活时间
* unit 存活的时间单位
* workQueue 存放提交但未执行任务的队列
* threadFactory 创建线程的工厂类:可以省略
* handler 等待队列满后的拒绝策略:可以省略
*/
return new ThreadPoolExecutor(0,
Integer.MAX_VALUE,
60L,
TimeUnit.SECONDS,
new SynchronousQueue<>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
}
场景:
适用于创建一个可无限扩大的线程池,服务器负载压力较轻,执行时间较短,任务多的场景
(2)newFixedThreadPool(常用)
作用
:创建一个可重用固定线程数的线程池,以共享的无界队列方式来运行这些线程。在任意点,在大多数线程会处于处理任务的活动状态。如果在所有线程处于活动状态时提交附加任务,则在有可用线程之前,附加任务将在队列中等待。如果在关闭前的执行期间由于失败而导致任何线程终止,那么一个新线程将代替它执行后续的任务(如果需要)。在某个线程被显式地关闭之前,池
中的线程将一直存在。
特征:
•
线程池中的线程处于一定的量,可以很好的控制线程的并发量
•
线程可以重复被使用,在显示关闭之前,都将一直存在
•
超出一定量的线程被提交时候需在队列中等待
创建方式
java"> /**
* 固定长度线程池
* @return
*/
public static ExecutorService newFixedThreadPool(){
/**
* corePoolSize 线程池的核心线程数
* maximumPoolSize 能容纳的最大线程数
* keepAliveTime 空闲线程存活时间
* unit 存活的时间单位
* workQueue 存放提交但未执行任务的队列
* threadFactory 创建线程的工厂类:可以省略
* handler 等待队列满后的拒绝策略:可以省略
*/
return new ThreadPoolExecutor(10,
10,
0L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
}
场景:
适用于可以预测线程数量的业务中,或者服务器负载较重,对线程数有严格限制的场景
(3)newSingleThreadExecutor(常用)
作用
:创建一个使用单个 worker 线程的 Executor,以无界队列方式来运行该线程。(注意,如果因为在关闭前的执行期间出现失败而终止了此单个线程,那么如果需要,一个新线程将代替它执行后续的任务)。可保证顺序地执行各个任务,并且在任意给定的时间不会有多个线程是活动的。与其他等效的newFixedThreadPool 不同,可保证无需重新配置此方法所返回的执行程序即可使用其他的线程。
特征:
线程池中最多执行 1 个线程,之后提交的线程活动将会排在队列中以此执行
创建方式:
java"> /**
* 单一线程池
* @return
*/
public static ExecutorService newSingleThreadExecutor(){
/**
* corePoolSize 线程池的核心线程数
* maximumPoolSize 能容纳的最大线程数
* keepAliveTime 空闲线程存活时间
* unit 存活的时间单位
* workQueue 存放提交但未执行任务的队列
* threadFactory 创建线程的工厂类:可以省略
* handler 等待队列满后的拒绝策略:可以省略
*/
return new ThreadPoolExecutor(1,
1,
0L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
}
场景:
适用于需要保证顺序执行各个任务,并且在任意时间点,不会同时有多个线程的场景
(4)newScheduleThreadPool(了解)
作用:
线程池支持定时以及周期性执行任务,创建一个 corePoolSize 为传入参数,最大线程数为整形的最大数的线程池**
特征:
(1)线程池中具有指定数量的线程,即便是空线程也将保留
(2)可定时或者延迟执行线程活动
创建方式:
java">public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize,
ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize,
threadFactory);
}场景: 适用于需要多个后台线程执行周期任务的场景
(5)newWorkStealingPool
jdk1.8 提供的线程池,底层使用的是 ForkJoinPool 实现,创建一个拥有多个任务队列的线程池,可以减少连接数,创建当前可用 cpu 核数的线程来并行执行任务
创建方式:
java"> public static ExecutorService newWorkStealingPool(int parallelism) {
/**
* parallelism:并行级别,通常默认为 JVM 可用的处理器个数
* factory:用于创建 ForkJoinPool 中使用的线程。
* handler:用于处理工作线程未处理的异常,默认为 null
* asyncMode:用于控制 WorkQueue 的工作模式:队列---反队列
*/
return new ForkJoinPool(parallelism,
ForkJoinPool.defaultForkJoinWorkerThreadFactory,
null,
true);
}
场景:
适用于大耗时,可并行执行的场景
4、线程池入门案例
场景: 火车站 3 个售票口, 10 个用户买票
java">/**
* 入门案例
*/
public class ThreadPoolDemo1 {
/**
* 火车站 3 个售票口, 10 个用户买票
*
* @param args
*/
public static void main(String[] args) {
//定时线程次:线程数量为 3---窗口数为 3
ExecutorService threadService = new ThreadPoolExecutor(3,
3,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy());
try {
//10 个人买票
for (int i = 1; i <= 10; i++) {
threadService.execute(() -> {
try {
System.out.println(Thread.currentThread().getName() + " 窗口, 开始卖票");
Thread.sleep(5000);
System.out.println(Thread.currentThread().getName() + " 窗口买票结束");
} catch (Exception e) {
e.printStackTrace();
}
});
}
} catch (Exception e) {
e.printStackTrace();
} finally {
//完成后结束
threadService.shutdown();
}
}
}5、注意事项
1. 项目中创建多线程时,使用常见的三种线程池创建方式,单一、可变、定长都有一定问题,原因是 FixedThreadPool 和 SingleThreadExecutor 底层都是用LinkedBlockingQueue 实现的,这个队列最大长度为 Integer.MAX_VALUE,容易导致 OOM。所以实际生产一般自己通过ThreadPoolExecutor 的 7 个参数,自定义线程池
2. 创建线程池推荐适用 ThreadPoolExecutor 及其 7 个参数手动创建
- corePoolSize 线程池的核心线程数
- maximumPoolSize 能容纳的最大线程数
- keepAliveTime 空闲线程存活时间
- unit 存活的时间单位
- workQueue 存放提交但未执行任务的队列
- threadFactory 创建线程的工厂类
- handler 等待队列满后的拒绝策略
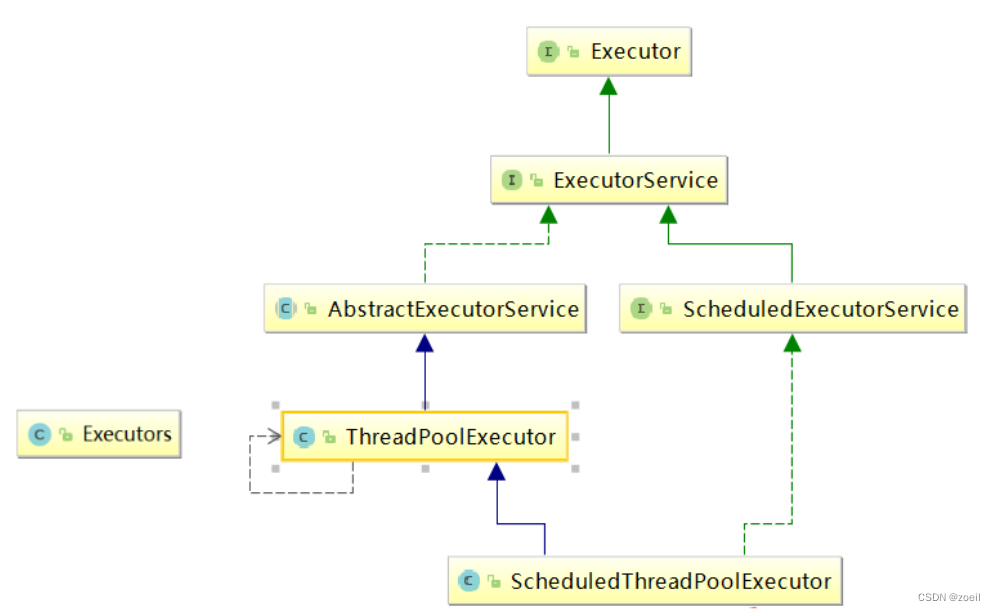
3. 为什么不允许适用不允许 Executors.的方式手动创建线程池,如下图

二、Fork/Join
1、框架简介
Fork/Join 它可以将一个大的任务拆分成多个子任务进行并行处理,最后将子任务结果合并成最后的计算结果,并进行输出。Fork/Join 框架要完成两件事情
Fork:把一个复杂任务进行分拆,大事化小Join:把分拆任务的结果进行合并
1.
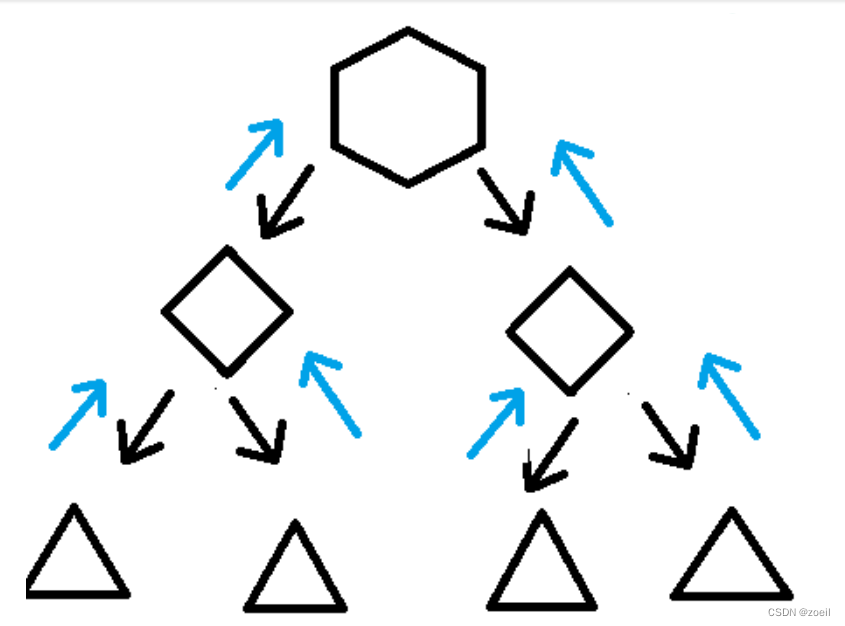
任务分割
:首先 Fork/Join 框架需要把大的任务分割成足够小的子任务,如果子任务比较大的话还要对子任务进行继续分割
2.
执行任务并合并结果
:分割的子任务分别放到双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都放在另外一个队列里,启动一个线程从队列里取数据,然后合并这些数据。
在 Java 的 Fork/Join 框架中,使用两个类完成上述操作
•
ForkJoinTask
:我们要使用 Fork/Join 框架,首先需要创建一个 ForkJoin 任务。
该类提供了在任务中执行 fork 和 join 的机制。通常情况下我们不需要直接集成 ForkJoinTask 类,只需要继承它的子类,Fork/Join 框架提供了两个子类:
- RecursiveAction:用于没有返回结果的任务
- RecursiveTask:用于有返回结果的任务
•
ForkJoinPool
:ForkJoinTask 需要通过 ForkJoinPool 来执行
•
RecursiveTask
: 继承后可以实现递归(自己调自己)调用的任务
Fork/Join 框架的实现原理
ForkJoinPool 由 ForkJoinTask 数组和 ForkJoinWorkerThread 数组组成,ForkJoinTask 数组负责将存放以及将程序提交给 ForkJoinPool,而 ForkJoinWorkerThread 负责执行这些任务。
当我们调用 ForkJoinTask 的 fork 方法时,程序会把任务放在 ForkJoinWorkerThread 的 pushTask 的 workQueue
中,异步地执行这个任务,然后立即返回结果
2、案例
场景: 生成一个计算任务,计算 1+2+3.........+1000
,
==每 100 个数切分一个
子任务==
java">class MyTask extends RecursiveTask<Integer> {
//拆分差值不能超过10,计算10以内运算
private static final Integer VALUE = 10;
private int begin ;//拆分开始值
private int end;//拆分结束值
private int result ; //返回结果
//创建有参数构造
public MyTask(int begin,int end) {
this.begin = begin;
this.end = end;
}
//拆分和合并过程
@Override
protected Integer compute() {
//判断相加两个数值是否大于10
if((end-begin)<=VALUE) {
//相加操作
for (int i = begin; i <=end; i++) {
result = result+i;
}
} else {//进一步拆分
//获取中间值
int middle = (begin+end)/2;
//拆分左边
MyTask task01 = new MyTask(begin,middle);
//拆分右边
MyTask task02 = new MyTask(middle+1,end);
//调用方法拆分
task01.fork();
task02.fork();
//合并结果
result = task01.join()+task02.join();
}
return result;
}
}
public class ForkJoinDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
//创建MyTask对象
MyTask myTask = new MyTask(0,100);
//创建分支合并池对象
ForkJoinPool forkJoinPool = new ForkJoinPool();
ForkJoinTask<Integer> forkJoinTask = forkJoinPool.submit(myTask);
//获取最终合并之后结果
Integer result = forkJoinTask.get();
System.out.println(result);
//关闭池对象
forkJoinPool.shutdown();
}
}