0、前言
我们知道,缓存由于在内存中,数据处理速度比直接操作数据库要快很多,因此常常将数据先读到缓存中,再进行查询、更新等操作。
但与之而来的问题就是,内存中的数据不仅没有持久化,而且需要保证redis和数据库中数据的一致性,针对这个问题,redis如何保证这样的一致性有以下几种策略。
1、Write Back(写回)策略
实际开发中最不常用的策略,它仅针对非敏感数据、一致性要求不强的数据,才有可能采用。实际开发不采用。
Write Back(写回)策略先把数据读入redis,在更新数据的时候,只更新缓存,同时将缓存数据设置为脏的,然后立马返回,并不会更新数据库。对于数据库的更新,会通过批量异步更新的方式进行,例如设置定时任务进行更新。
例如,对于博客浏览量这样的数据,我们采用写回策略,即使多个用户并发访问,我们每次只要把缓存中的浏览量更新即可,这种 写回策略 非常适合发生大量写操作的场景。
也就是说,读写都在redis中进行,然后异步地更新回数据库来保持一致性、持久化。
明显的缺点:带来的问题是,数据不是强一致性的,而且会有数据丢失的风险。因为缓存一般使用内存,而内存是非持久化的,所以一旦缓存机器掉电,就会造成原本缓存中的脏数据丢失。
2、Read/Write Through(读穿 / 写穿)策略
(1)Read Through 策略
先查询缓存中数据是否存在,如果存在则直接返回,如果不存在,则由缓存组件负责从数据库查询数据,并将结果写入到缓存组件,最后缓存组件将数据返回给应用。
(2)Write Through 策略
当有数据更新的时候,先查询要写入的数据在缓存中是否已经存在:
3、Cache Aside 旁路缓存 策略(实际开发常用)
实际开发中,前两种策略都用不了,而采用旁路缓存策略,只不过有一些难度和注意点。
先说正确结论:
写策略的步骤:
读策略的步骤:
(1)数据库和缓存都要更新?
如果叛逆一点,更新数据库,更新缓存,会带来怎样的并发问题呢?
借用小林coding的时序图如下:
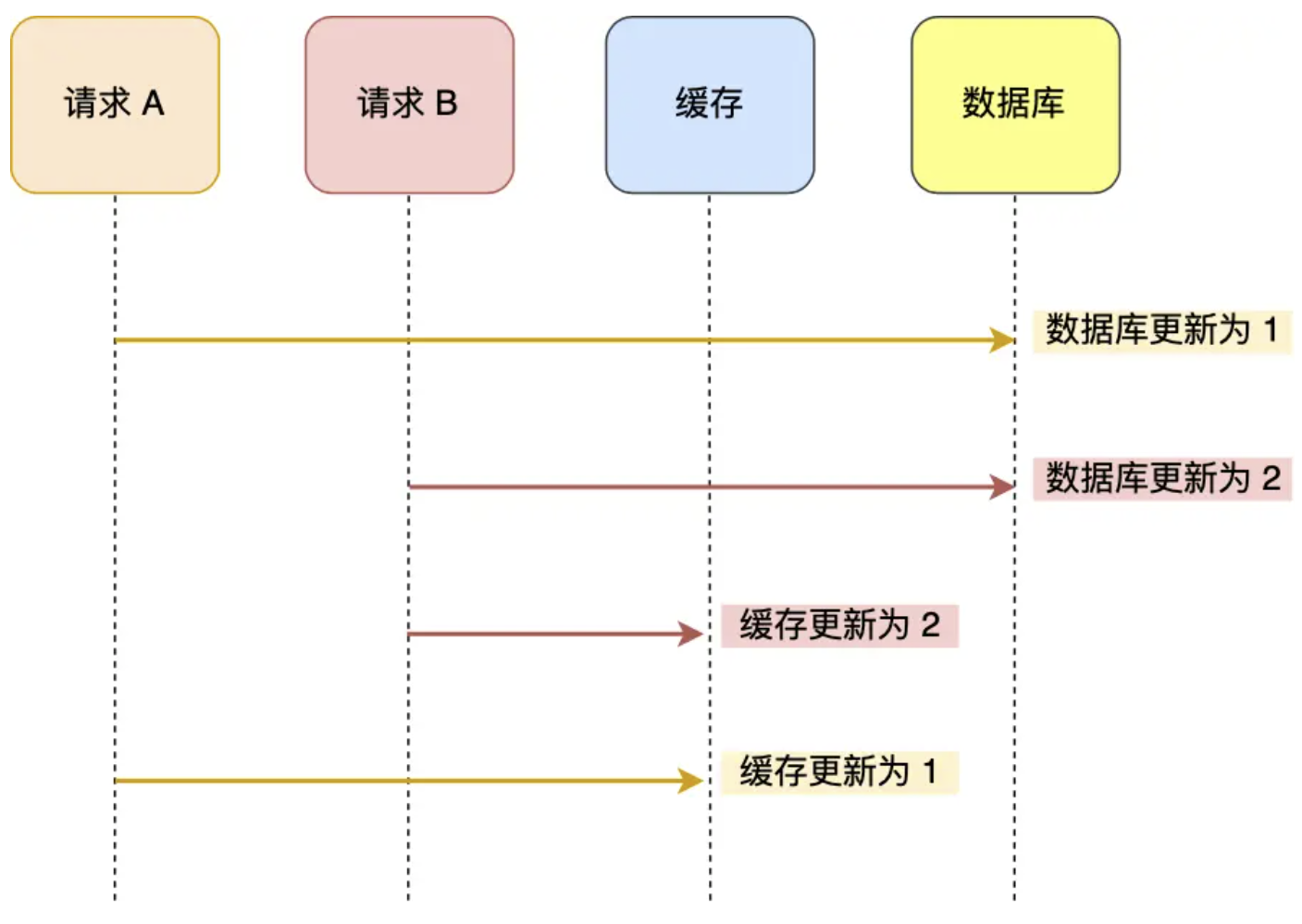
假设请求A、B同时对数据更新,顺序如下,在并发情况下,有可能先更新的请求A还没有更新完的时候,请求B就把缓存都更新完事了,然后A再更新缓存。
可见,这样会造成数据库为2、缓存为1,也就是不一致状况。而如果先更新缓存再更新数据库也是同理的,仍然有数据不一致问题。
(2)改进:只更新数据库,不更新缓存了,直接把缓存中的数据删了
反正就算redis里没数据,查询时也会从数据库里查出来放在redis里,那我直接不更新了!把数据删了,到时候再读不就好了!这就是Cache Aside 策略。
<1> 假设我们先删除缓存,引用小林的图片:线程A先删除缓存再更新数据库为“21”,但由于更新写入数据库的速度是慢很多的,很可能中间出现了请求B在做查询,从而读取到还未更新的值“20”,并把缓存更细。从而导致不一致问题,这是不允许的。

<2> 这次改邪归正,我们先更新数据库,再删除缓存:有人会觉得请求A如果去查询数据时,如果缓存未命中,在把数据写回redis的过程中,线程B过来先更新再删除,那就会导致如下的不一致情况了吗?!
但实际上这样的情况很少,根本原因在于:update数据库的速度 比 update缓存的速度 要慢得多。
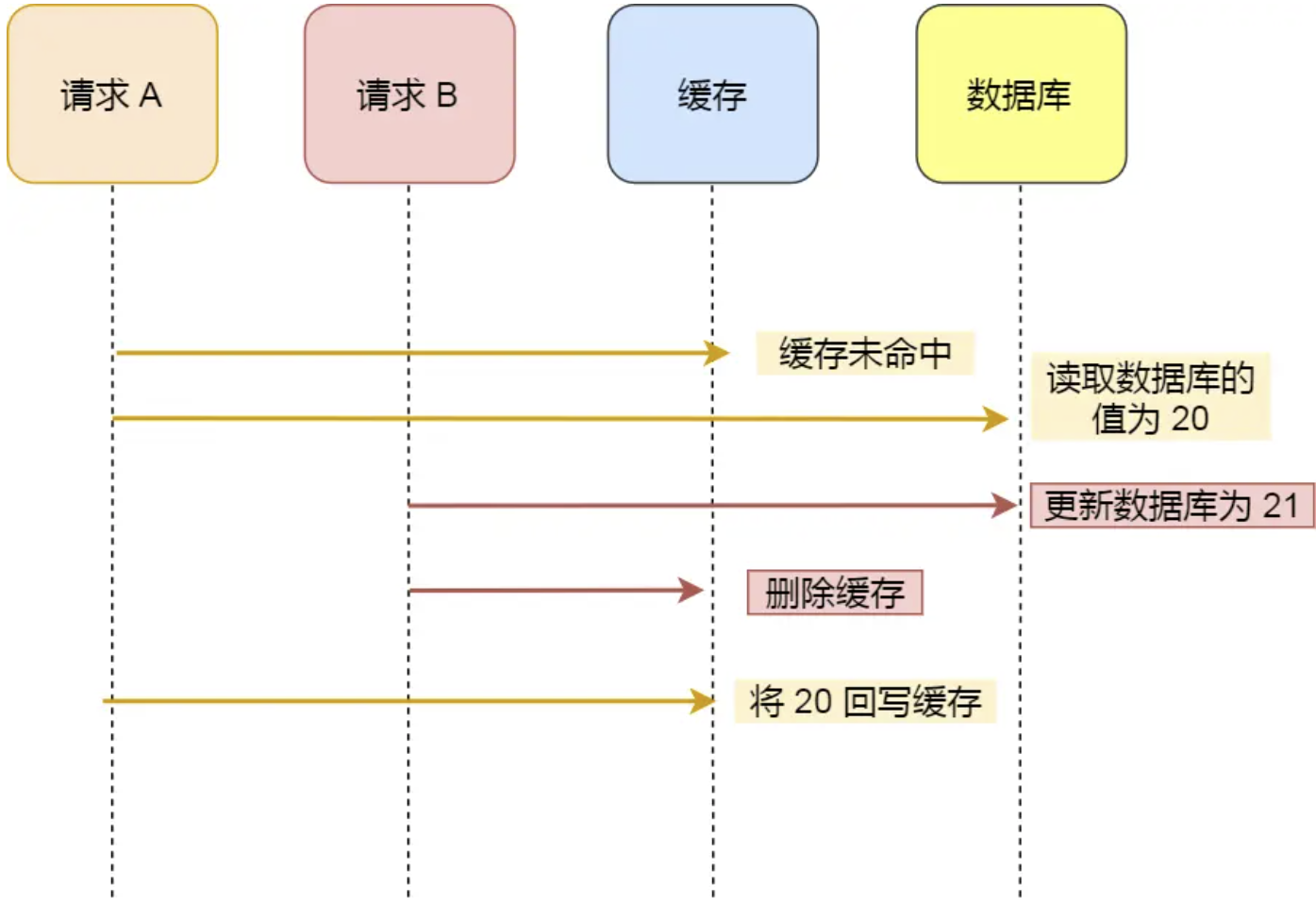
也就是说,黄色线条中间,更新缓存的时间间隔是很短的,而更新数据库的时间相对要慢得多,因此这种并发问题很罕见,还是能保证一致性的。
(3)再改进:如果“删除缓存”这个步骤失败了怎么办?
为了确保万无一失,我们可以给缓存数据加了过期时间,就算在这期间存在缓存数据不一致,但过期时间到了会自动清除redis的key,这样也能避免删除失败的问题,达到最终一致。
但问题在于,如果删除失败需要等待过期时间,数据的时效性、一致性就不强了,有可能明明更新了数据,查询显示出来却要过一段时间才生效,这对敏感业务来说是有影响的!
解决方案:使用消息队列实现异步处理
在消费者线程中,尝试删除缓存。
如果删除失败,则根据任务是否在消息队列中进行判断,若在队列中,则继续重试;否则报错。
如果删除成功,才将任务从消息队列中移除。示例代码如下:
java">import redis.clients.jedis.Jedis;
import redis.clients.jedis.exceptions.JedisException;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class CacheManager {
private Jedis redisClient;
private BlockingQueue<String> messageQueue;
public CacheManager() {
// 初始化Redis连接和消息队列
redisClient = new Jedis("localhost");
messageQueue = new LinkedBlockingQueue<>();
// 创建并启动消费者线程
Thread consumerThread = new Thread(new Consumer());
consumerThread.start();
}
public void deleteCache(String key) {
// 将任务添加到消息队列中
String task = key;
try {
messageQueue.put(task);
System.out.println("Added cache delete task for key: " + key);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private class Consumer implements Runnable {
@Override
public void run() {
while (true) {
try {
String task = messageQueue.take();
// 尝试删除缓存
try {
// 删除缓存的操作,此处为示例代码,根据实际情况进行修改
redisClient.del(task);
System.out.println("Deleted cache for key: " + task);
} catch (JedisException e) {
// 删除失败,重试或报错
if (messageQueue.contains(task)) {
// 仍在队列中,继续重试
System.out.println("Failed to delete cache for key: " + task + ", retrying...");
messageQueue.put(task);
} else {
// 不在队列中,报错
System.out.println("Failed to delete cache for key: " + task + ", max retries exceeded. Reporting error...");
}
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public static void main(String[] args) {
CacheManager cacheManager = new CacheManager();
// 示例使用
cacheManager.deleteCache("user:1");
cacheManager.deleteCache("user:2");
}
}
4、小结
本文通过介绍多种缓存更新策略,以及深入理解了实际开发中常用的旁路缓存策略所遇到的问题,并通过消息队列进行改进,实现了缓存与数据库的一致性。