文章目录
- 前言
- 源码注释
- 术语
- 节点定义
- 构造器
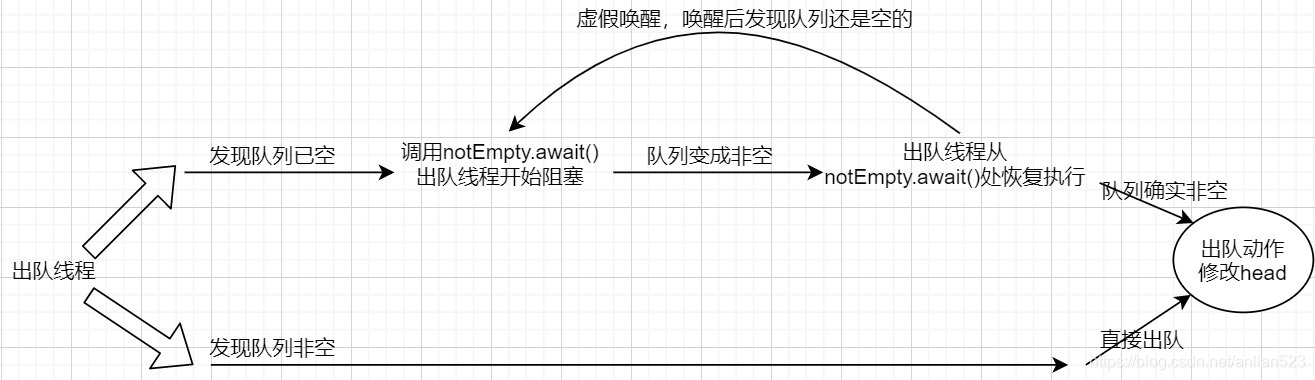
- get 查找操作
- 返回情况
- findPredecessor
- put 插入操作
- 假设新建层数没有超过最大层数
- 假设新建层数超过了最大层数
- 返回情况
- remove 删除操作
- findNode
- tryReduceLevel
- 返回情况
- marker存在的必要性
- 如果marker不存在
- marker存在时
- 总结
前言
ConcurrentSkipListMap是一个可以在高并发环境下执行的有序map容器,在单线程环境下我们应使用TreeMap,在低并发环境下我们可以使用Collections.synchronizedSortedMap包装TreeMap来得到一个线程安全的有序map。ConcurrentSkipListMap底层实现是一个SkipList跳表,简单的说就是一个稍微复杂一点的链表结构。
JUC框架 系列文章目录
源码注释
* Head nodes Index nodes
* +-+ right +-+ +-+
* |2|---------------->| |--------------------->| |->null
* +-+ +-+ +-+
* | down | |
* v v v
* +-+ +-+ +-+ +-+ +-+ +-+
* |1|----------->| |->| |------>| |----------->| |------>| |->null
* +-+ +-+ +-+ +-+ +-+ +-+
* v | | | | |
* Nodes next v v v v v
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
* | |->|A|->|B|->|C|->|D|->|E|->|F|->|G|->|H|->|I|->|J|->|K|->null
* +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+ +-+
上面这段注释已经给出了跳表的基本样子,最底层是base层用来存储数据,其他层都是index层用来加快搜索。可见不管是base层还是index层,第一个节点实际上是不存储真实数据的,而是作为一个dummy节点存在。真正的节点只会在第二个节点开始存储。
The basic idea in these lists is to mark the “next” pointers of deleted nodes when deleting to avoid conflicts with concurrent insertions, and when traversing to keep track of triples (predecessor, node, successor) in order to detect when and how to unlink these deleted nodes.
这些链表中的基本思想是在删除时标记已删除节点的next指针,以避免与并发插入发生冲突,并且在遍历以跟踪三元组(前驱,节点,后继)时进行标记,以检测何时以及如何取消链接 这些已删除的节点。——可能看完还是有点不懂,我们继续。
删除节点的具体过程如下:
假设在base层中间有这么一段节点,我们想要删除n:
* +------+ +------+ +------+
* ... | b |------>| n |----->| f | ...
* +------+ +------+ +------+
- 将n的value置为null,代表它被标记为删除节点了。从此刻开始,后续的public操作都不会遍历经过n节点了,但正在进行中的插入和删除操作(它们没有检测到
n的value为null),可能会去尝试修改n的后继。 - 在n和f之间插入一个marker,这个marker的key为null,value指向自己。从此刻开始,任何节点都不可能添加到n后面了。
* +------+ +------+ +------+ +------+
* ... | b |------>| n |----->|marker|------>| f | ...
* +------+ +------+ +------+ +------+
- 将b的next指向f,从此刻开始,任何遍历都不可能遇到n了,n将会被gc回收掉。
* +------+ +------+
* ... | b |----------------------------------->| f | ...
* +------+ +------+
一个节点的删除过程必须经过这三个步骤,而且必须以这个顺序执行,这就是删除节点过程的“状态机”。
术语
- base层:最下面的层(第0层),节点类型为
Node。 - index层:第1层或以上,节点类型为
Index。 - node节点:base层的节点。
- index节点:index层的节点。
- headIndex节点:index层的头节点。
- marker:不存储数据,只是为了删除时使用。
- 被标记为删除:
Node的value为置为null。简称为“被标记”。
节点定义
static final class Node<K,V> {
final K key;
volatile Object value;
volatile Node<K,V> next;
Node(K key, Object value, Node<K,V> next) {//正常构造node
this.key = key;
this.value = value;
this.next = next;
}
Node(Node<K,V> next) {//构造marker
this.key = null;
this.value = this;
this.next = next;
}
}
这个是base层的node节点的定义,是真正存储数据的层,也是跳表的最底层。node节点只有right指针。
static class Index<K,V> {
final Node<K,V> node;
final Index<K,V> down;
volatile Index<K,V> right;
Index(Node<K,V> node, Index<K,V> down, Index<K,V> right) {
this.node = node;
this.down = down;
this.right = right;
}
}
这个是index层的index节点的定义,用来跳跃寻找目标。index节点有right和down指针。
static final class HeadIndex<K,V> extends Index<K,V> {
final int level;
HeadIndex(Node<K,V> node, Index<K,V> down, Index<K,V> right, int level) {
super(node, down, right);
this.level = level;
}
}
这个是每个index层的头节点,作为一个dummy节点使用。它多了一个level属性用来index层的层数。

一个跳表的结构可能如上图所示。虽然index节点里也有数字,但这只是为了方便看图,index其实并没有直接存储数据。如果单独拎出来一列的话,它是这样的:

构造器
//不指定Compartor的话,则key肯定是Comparable子类对象
public ConcurrentSkipListMap() {
this.comparator = null;
initialize();
}
public ConcurrentSkipListMap(Comparator<? super K> comparator) {
this.comparator = comparator;
initialize();
}
private void initialize() {
keySet = null;
entrySet = null;
values = null;
descendingMap = null;
// private static final Object BASE_HEADER = new Object();
// 下面new的node节点,作为base层的dummy节点存在
head = new HeadIndex<K,V>(new Node<K,V>(null, BASE_HEADER, null),
null, null, 1);
}
可见初始的时候,只有base层和一层index层,而且这两层都只有一个dummy节点作为头节点。
get 查找操作
public V get(Object key) {
return doGet(key);
}
private V doGet(Object key) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {//b作为被找到的前驱
Object v; int c;
if (n == null)//b的后继为null,说明寻找目标不存在
break outer;
Node<K,V> f = n.next;
// 此时三个node的关系应该是b--->n--->f
if (n != b.next) // 如果n已经不是b的后继,从头开始循环以执行单次表达式
break;
if ((v = n.value) == null) { // n的value为null代表n被删除
n.helpDelete(b, f); //进行base层的删除活动
break;
}
if (b.value == null || v == n) //如果b被标记或n是个marker,说明b被删除
break;
if ((c = cpr(cmp, key, n.key)) == 0) {//说明目标为找到,就是n
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
if (c < 0)//说明目标不存在,因为 b <目标 < n
break outer;
//if (c > 0) 执行右移操作
b = n;
n = f;
}
}
return null;
}
发现有一个很奇怪的双层死循环,我们要看懂ConcurrentSkipListMap的代码,一定要先搞懂这个。外层死循环仅仅是在内层套了一个壳子,实际没有做什么。退出循环有两种方式:
- 内循环中执行
break,然后退出内循环,执行到外循环的末尾,又会从新开始执行内循环。重点在于会从新执行一遍Node<K,V> b = findPredecessor(key, cmp), n = b.next,顺便重置两个局部变量b n。 - 内循环中执行
break outer,才会退出双层循环。
findPredecessor负责在index层寻找一个<参数key但最接近参数key的index节点的node成员,所以doGet的主要逻辑都是base层活动。局部变量的结构为b--->n--->f,目标被找到时,n会指向目标。
主要逻辑前面进行了一些必须的判断,一旦发现情况不对,就break退出内循环重新开始。所以我们重点在于分析比较结果c:
- 如果
c等于0,说明目标被找到。 - 如果
c小于0,说明目标不存在,因为b < 目标 < n。 - 如果
c大于0,说明目标如果存在,只能在n的后面,所以需要执行右移操作。- 如果右移后,发现
b已经到了base层末尾,同样说明目标不存在(if (n == null)分支)。
- 如果右移后,发现
返回情况
- 目标能找到,返回目标的value。
- 目标不能找到,返回null。
findPredecessor
/**
* 该函数只在index层里寻找<参数key的那个index节点,并返回这个index节点的node成员。
* 如果能找到,那么返回一个真实的node;否则返回base层的header(一个dummy node)。
* 在寻找的过程中还会断开与删除的index节点的链接。
* @param key 要寻找的目标
* @return 目标的前驱,目标如果存在,那么肯定在前驱的后面
*/
private Node<K,V> findPredecessor(Object key, Comparator<? super K> cmp) {
if (key == null)
throw new NullPointerException(); // don't postpone errors
for (;;) {
//q和r肯定是处于同一index层的两个相邻index节点
for (Index<K,V> q = head, r = q.right, d;;) {
if (r != null) {//先判断q是否需要右移
Node<K,V> n = r.node;
K k = n.key;
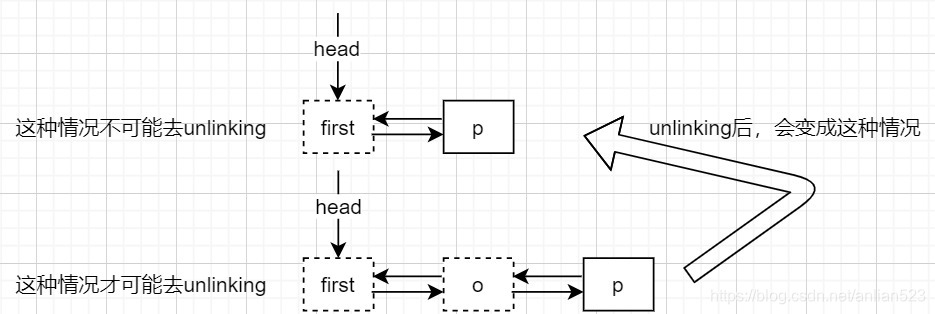
if (n.value == null) {//如果r的node已经被标记为删除
if (!q.unlink(r))//断开q与r的连接,进而和r的右节点连接
break; // 如果断开操作失败,说明被其他线程抢先了。整个跳表结构发生变化,需要从新循环
r = q.right; // 如果断开操作成功,那么更新r后,开始下一次循环
continue;
}
//执行到这里,说明r的node没有被标记为删除(上面的逻辑不是break就是continue)
if (cpr(cmp, key, k) > 0) {//目标比r的node大,说明r肯定在目标的前面,但不一定是参数的前驱,先右移再说。
//注意,等于的情况不会右移,这是为了保证找到目标的前驱而不是找到目标
q = r;//右移,更新q和r
r = r.right;
continue;
}
}
//执行到这里,说明之前判断了不能右移(r存在,但目标 <= r的node),
//或者r根本存在,只能下移
if ((d = q.down) == null)//判断q是否已经被找到
//如果q的down为null,说明q已经是最低的index层的,该函数任务完全,返回q的node即可
return q.node;
//q没有被找到,必须下移
q = d;
r = d.right;
}
}
}
if (r != null)分支,判断是否需要右移。如果同时发现了r的node成员被标记为null了,还会通过unlink断开 应删除index 左右的连接。- 由于查询路径优先右移(下面解释),所以一个被标记的node节点的垂直方向的index们,最终都会被
findPredecessor检测到,从而断开与这些index的连接。
- 由于查询路径优先右移(下面解释),所以一个被标记的node节点的垂直方向的index们,最终都会被
- 如果判断不需要右移,那么接下来就会判断是否找到目标(
if ((d = q.down) == null))。还是没有找到目标,则下移。(先右移,后下移) - 该函数保证返回目标的前驱,不管目标是否存在。
- 局部变量的结构为
q--->r,目标被找到时,r的node成员会指向目标。

如上图所示,如果查找目标是27,那么经过findPredecessor只能返回22,因为该函数只能在index层里面寻找。

如上图所示,展示了findPredecessor附带的清理index节点的功能。假设30这个node节点已经被标记为null(即标记为删除),在执行findPredecessor的过程,肯定会检测到30的两个index节点,然后断开30左右的连接。
并且,以上图为例,只要是30以下的node节点被删除(考虑目标是<=30的),它们的index节点肯定会被findPredecessor清理掉。
put 插入操作
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);//onlyIfAbsent默认false
//如果找到相等key,将执行替换操作
}
doPut函数的逻辑有点多,将其分为三个部分。从上下的检查来看,它不允许存储null的key和value。
//第一部分
private V doPut(K key, V value, boolean onlyIfAbsent) {
Node<K,V> z; // 如果最终是增加node,而不是替换node的value。那么z保存新增node引用
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {//b是一个<参数key,但接近key的node
if (n != null) {
Object v; int c;
Node<K,V> f = n.next;
if (n != b.next) // 如果n在这段时间内被移除掉了,退出内循环重试,这样就可以n = b.next重新读取b的后继
//这种情况说明b的后继被并发修改了
break;
if ((v = n.value) == null) { // n的value为null说明被标记删除,使用helpDelete
n.helpDelete(b, f);//根据helpDelete的逻辑,如果没有并发线程帮忙,连续两次循环都会执行这句
break;
}
//执行到这里,说明n还是b的后继,且n没有被删除
if (b.value == null || v == n) // b被标记删除,或n是一个marker。说明b被删除了
break;
//执行到这里,说明n还是b的后继,且n和b都没有被删除
if ((c = cpr(cmp, key, n.key)) > 0) {//如果参数key大于n
b = n;//b和n整体右移
n = f;
continue;//继续下一次循环
}
if (c == 0) {//n和参数key相等,说明map中存在与参数key相同的key
//1. onlyIfAbsent为true将不会执行替换操作
//2. onlyIfAbsent为false那么将尝试CAS修改value,CAS操作成功则此函数任务完成
//两种情况都将返回旧值
if (onlyIfAbsent || n.casValue(v, value)) {
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;
}
//执行到这里,说明onlyIfAbsent为false,且CAS操作失败了
break; // 说明别的线程修改value成功了,需要从头开始循环
}
// 如果c < 0说明在base层找到了<=参数key,但最接近key的node
}
//只有在找到目标插入位置时(map中没有找到相等的key,所以必须插入),才执行下面这段代码
z = new Node<K,V>(key, value, n);//先令z指向n
if (!b.casNext(n, z))
break; // CAS操作失败,b的后继被更换,需要从头开始循环
break outer;//如果CAS操作成功,那么退出双层循环
}
}
//执行到这里,说明新node z已经创建
第一部分的主要逻辑是新建一个新node,或者替换已存在node的value,如果新建了node那么将保存在外面的局部变量z上。
整个第一部分代码只在base层活动,因为findPredecessor已经返回一个node节点,目标插入位置只能在这个node节点之后,通过不断右移,最终找到目标插入位置(b-->n的中间位置)。
如果替换已存在node的value,第一部分里将直接return,从而导致函数退出。所以接下来分析第二部分代码,则假设第一部分的操作为新建一个新node。
int rnd = ThreadLocalRandom.nextSecondarySeed();
if ((rnd & 0x80000001) == 0) { // 如果最高bit和最低bit都是0
/*第二部分*/
/*第三部分*/
}
第二部分和第三部分处于同一个if分支里面,通过ThreadLocalRandom.nextSecondarySeed()获得一个int型的随机数(它与线程无关),如果这个int型的最高bit和最低bit都是0(这种可能性挺大),那么将进入分支。分支内的逻辑为:为新建node创建垂直方向的index,所以如果没有进入分支,那说明这个新建node的垂直方向上将没有index节点。
int rnd = ThreadLocalRandom.nextSecondarySeed();
if ((rnd & 0x80000001) == 0) { // 如果最高bit和最低bit都是0
/*第二部分*/
int level = 1, max;
while (((rnd >>>= 1) & 1) != 0)//每当中间bit有一个是1
++level;
Index<K,V> idx = null;
HeadIndex<K,V> h = head;
/*第一种情况*/
if (level <= (max = h.level)) {//如果要建立的index层没超过最大层数
for (int i = 1; i <= level; ++i)
//自低向上建立index,但每个新建index的前后的right指针还没好
idx = new Index<K,V>(z, idx, null);
//注意第一个创建的index的down指针为null,因为它处于最底层的index层
}
/*第二种情况*/
else { //如果要建立的index层超过了最大层数,就建立最大层加1
level = max + 1;
// 从1到level的数组索引,用来放从1到level的新建index
@SuppressWarnings("unchecked")Index<K,V>[] idxs =
(Index<K,V>[])new Index<?,?>[level+1];//0元素不使用
for (int i = 1; i <= level; ++i)
//自低向上建立index,但每个新建index的前后的right指针还没好
idxs[i] = idx = new Index<K,V>(z, idx, null);
//依次放在数组里
for (;;) {
h = head;
int oldLevel = h.level;//head当前的层数
if (level <= oldLevel) // 如果当前层数已经大于等于了想要创建的层数,说明有线程抢先一步增加了head所在层
break;//那么便不需要执行此循环了
HeadIndex<K,V> newh = h;
Node<K,V> oldbase = h.node;
//从当前层数oldLevel到想要创建的层数level,还需要执行循环这么多次
//有可能head的所在层数相比max减小了,此时max与oldLevel不相等,进而下面循环可能执行多次而不是一次
for (int j = oldLevel+1; j <= level; ++j)
newh = new HeadIndex<K,V>(oldbase, newh, idxs[j], j);
//自低向上建立HeadIndex,且每个HeadIndex的right也指好了
if (casHead(h, newh)) {//如果CAS设置head成功,那么此循环任务完成,将退出该循环
//退出之前把h局部变量更新为当前head
h = newh;
//level和idx局部变量分别更新为,旧head的层数,和处于这一层的index
idx = idxs[level = oldLevel];
break;
}
}
}
第二部分的代码主要是用来为新建node创建垂直方向的index。而垂直方向的index们的层数由随机数的中间bit决定,分为两种情况:
- 如果要创建的index层的层数
level小于等于当前最大层数head.level,那么说明只需要创建index节点就好,不需要创建headIndex节点了,因为每层的headIndex节点都已经存在了。正如if (level <= (max = h.level))分支做的一样。 - 如果要创建的index层的层数
level大于当前最大层数head.level,那么说明除了要创建index节点以外,还需要创建headIndex节点。正如if (level <= (max = h.level))的else分支做的一样。这种情况,不管开始level超过了最大层数多少,最终只创建最大层数+1的层(level = max + 1;)。 - 其实还有一种情况,就是
if (level <= (max = h.level))的else分支里面,如果发现head的层数由于并发而发生改变(这里特指head所在层数增加了),而进入了if (level <= oldLevel)分支,说明这又变成了第一种情况,即不需要创建headIndex节点了。
假设初始跳表如下:
考虑我们是第一种情况,那么最终结果如下:

可见因为新建的index节点们都还没有和前后的index左右相连,为保证第三部分能继续处理,则把idx停留在最高的需要左右相连的index节点上,并把level停留在idx所在的层数。
考虑我们是第二种情况,那么最终结果如下:

同样的,idx停留在最高的需要左右相连的index节点上,并把level停留在idx所在的层数。注意,如果是新建的index层(上图的index 4层),左右相连的任务已经完成了(new HeadIndex<K,V>(oldbase, newh, idxs[j], j),HeadIndex在构造时就连上了)。
不过第二种情况的新建的index层也可能不止1层,当读取int oldLevel = h.level读取旧head的层数时,可能获得的oldLevel已经比max小了,此时,需要新建level - oldLevel层数的index层,for (int j = oldLevel+1; j <= level; ++j)循环也会执行level - oldLevel次。
最重要的是,第二部分代码的两种情况都会把idx停留在最高的需要左右相连的index节点上,并把level停留在idx所在的层数。
/*第三部分*/
// 把需要左右相连的index连上
splice: for (int insertionLevel = level;;) {
int j = h.level;//获得最高层数
for (Index<K,V> q = h, r = q.right, t = idx;;) {
if (q == null || t == null)//第一次循环肯定不会进入此分支
//只是一种保护,一般不可能进入此分支
break splice;
if (r != null) {//先判断q和r是否需要右移
Node<K,V> n = r.node;
int c = cpr(cmp, key, n.key);
if (n.value == null) {//如果n被标记为删除
if (!q.unlink(r))//那么断开q和r这两个index之间的连接
break;//断开连接失败则退出内循环从新开始
r = q.right;//断开连接成功则更新r,开始下一次循环
continue;
}
if (c > 0) {//只要r是小于参数的,那么q和r右移
q = r;
r = r.right;
continue;
}
}
//执行到这里,说明不需要右移
//接下来这段代码刚开始不会执行,只有当--j执行数次后,
//直到j == insertionLevel后,那么之后的循环只要执行到这里,都会进入此分支
if (j == insertionLevel) {
if (!q.link(r, t))//执行成功后 q-->t-->r,即t变成q新的后继
break; // 连接失败则退出内循环从新开始
if (t.node.value == null) {//t被标记为删除
findNode(key);//调用此函数,顺便删除掉被标记节点
break splice;//既然新增节点都被删除掉了,双层循环也该退出了
}
if (--insertionLevel == 0)//如果已经到达了base层,说明每个需要左右相连的index都已经左右相连了
break splice;
}
//执行到这里,接下来q和r和j都会下移,至于t,
//只要执行过了第二阶段,在这一行 insertionLevel <= j < level肯定成立,
//自然也会执行t = t.down
if (--j >= insertionLevel && j < level)
t = t.down;
q = q.down;
r = q.right;
}
}
}
第三部分代码可以分为三个阶段:
- 第一次进入
if (j == insertionLevel)分支之前。 - 正在执行第一次
if (j == insertionLevel)分支。 - 执行完第一次
if (j == insertionLevel)分支。
第一阶段:
- 简单的说,
if (r != null)分支将执行右移操作,因为是右移所以不用减小j。if (--j >= insertionLevel && j < level)这4行代码是下移操作(注意,这个分支在第一阶段不会进入,但--j是一定会执行的),因为是下移所以需要减小j。总之,j q r三者总是会在同一层上。 - 在第一次执行
if (j == insertionLevel)分支之前,不会去执行--insertionLevel的。也就是说,在这个时间点之前,insertionLevel == level是成立的,自然if (--j >= insertionLevel && j < level)永远也不会成立(不可能既大于等于一个数,又小于同一个数),也就不会去执行t = t.down。- 总之,在第一阶段的
q r下移过程中,t是一直保持不变的。
- 总之,在第一阶段的
第二阶段:
- 正在执行第一次
if (j == insertionLevel)分支,说明即将处理最高的需要左右相连的index节点t了,相连后结构为q-->t-->r。 - 注意还会执行
--insertionLevel,执行后insertionLevel + 1 == level成立,紧接的if (--j >= insertionLevel && j < level)判断自然也会成立(此时insertionLevel + 1 == j + 1 == level),也就会去执行t = t.down。 if (--insertionLevel == 0) break splice;这是第三部分代码正常退出时的分支,当insertionLevel到达base层后(变成0),说明每一个需要左右相连的index节点都已经左右相连了。
第三阶段:
- 根据上一条分析,第三阶段的
q r下移过程中,t也会跟着下移的。 - 每次执行下移操作之前,会进入
if (j == insertionLevel)分支去处理需要左右相连的index节点。
假设新建层数没有超过最大层数
我们以第二部分代码的第一种情况为例开始画图分析:
第一阶段的整个过程如下:

第二阶段:

第三阶段:

假设新建层数超过了最大层数
我们再以第二部分代码的第二种情况为例开始画图分析,由于过程类似,则只画出每一阶段的最后结果:
第一阶段——最终结果:

第二阶段:

第三阶段——最终结果:

返回情况
前面三个部分分析完,还有最后一点代码。
return null;
}
如果put函数的操作是新建node,那么肯定会返回null。相反,如果是替换操作(或者根本没替换,因为onlyIfAbsent为true),则肯定返回旧value。
remove 删除操作
public V remove(Object key) {
return doRemove(key, null);//第二个参数是null
}
doRemove的逻辑的前半段,其实和findNode和doGet都比较像,只是最后在判断比较结果c时,处理有所不同。
final V doRemove(Object key, Object value) {
if (key == null)
throw new NullPointerException();
Comparator<? super K> cmp = comparator;
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null)//b到达base层的最右节点,都没有找到key,退出双层循环
break outer;
Node<K,V> f = n.next;
//b-->n-->f的结构
if (n != b.next) //由于并发,n不是b的后继了
break;
if ((v = n.value) == null) { //如果n被标记为删除
n.helpDelete(b, f); //如果没有别的线程帮忙,helpDelete会执行两次
break;
}
if (b.value == null || v == n) //如果b被标记为删除,或者n是个marker
break;
if ((c = cpr(cmp, key, n.key)) < 0)//如果n已经大于参数key,说明想删除的元素不存在
break outer;
if (c > 0) {//如果n小于参数key,说明想删除的元素只可能在n后面,b n后移
b = n;
n = f;
continue;//继续下一次循环
}
//执行到这里,说明c为0,想删除元素已经被找到,那就是n
if (value != null && !value.equals(v))//如果value不为null,那么必须检查n和value
break outer;
if (!n.casValue(v, null))//如果别的线程并发修改了n的value
break;
//执行到这里,说明删除成功了,准确的说是标记删除成功了
if (!n.appendMarker(f) || !b.casNext(n, f))
//只要有一个操作执行失败,进入此分支
findNode(key); //因为findNode会调用helpDelete,helpDelete会做上面的两个操作
else {
//只有两个操作都成功了,进入此分支(把查找路径上遇到的应删除的index节点给断开连接)
findPredecessor(key, cmp);
//有可能之前最高层只有head和一个index,然后findPredecessor把这个index断开连接
//此时最高层需要降低
if (head.right == null)
tryReduceLevel();
}
@SuppressWarnings("unchecked") V vv = (V)v;
return vv;//只要是删除成功的,就返回旧value
}
}
return null;//其他情况都返回null
}
既然前半段都类似,我们直接来看比较结果c的不同处理:
- 如果
c大于0,说明n已经大于参数key了,而key肯定比b大,所以不用继续寻找了,因为肯定不存在。 - 如果
c小于0,说明n小于参数key了,如果key存在的话,肯定在n的后面,所以需要b n右移。 - 如果
c等于0,说明n就是我们想要删除的node。
findNode
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // retry via findNode
else {
findPredecessor(key, cmp); // clean index
if (head.right == null)
tryReduceLevel();
}
在删除成功后将执行上面这段代码。
| n.appendMarker(f) | b.casNext(n, f) | 效果 | 解释 |
|---|---|---|---|
| 返回false | 被短路,不执行 | 进入if分支 | base层的删除未完成 |
| 返回true | 返回false | 进入if分支 | base层的删除未完成 |
| 返回true | 返回true | 进入else分支 | base层的删除完成 |
从上表可知,只要有一个操作执行失败,就会调用findNode,里面又会去调用helpDelete,而helpDelete的两种操作,其实就分别是n.appendMarker(f)和b.casNext(n, f)。
- 进入if分支,代表base层和index层里都需要清理掉,应删除node 和 应删除index。而
findNode的逻辑将清理node,findNode调用的findPredecessor将清理index。 - 进入else分支,代表只有index层需要清理。所以只需要调用
findPredecessor。
尽管doRemove会做上面的这些善后操作,在成功删除以后。但在多线程环境下,别的线程很可能在当前线程执行善后操作之前,就发现 被标记为null 的node,所以本文的很多代码在遍历过程中都会一直判断节点是否被删除。
private Node<K,V> findNode(Object key) {
if (key == null)
throw new NullPointerException(); // don't postpone errors
Comparator<? super K> cmp = comparator;
outer: for (;;) {
for (Node<K,V> b = findPredecessor(key, cmp), n = b.next;;) {
Object v; int c;
if (n == null)
break outer;
Node<K,V> f = n.next;
if (n != b.next) // inconsistent read
break;
if ((v = n.value) == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (b.value == null || v == n) // b is deleted
break;
if ((c = cpr(cmp, key, n.key)) == 0)
return n;
if (c < 0)
break outer;
//if (c > 0)
b = n;
n = f;
}
}
return null;
}
findNode的前面逻辑很类似,我们只看c的判断就好:
- 如果
c等于0,说明找到了参数key。 - 如果
c小于0,说明参数key比b大比n小(结构b-->n),即参数key不存在。 - 如果
c大于0,说明参数key比n大,需要右移,继续寻找。
tryReduceLevel
Possibly reduce head level if it has no nodes. This method can (rarely) make mistakes, in which case levels can disappear even though they are about to contain index nodes. This impacts performance, not correctness. To minimize mistakes as well as to reduce hysteresis, the level is reduced by one only if the topmost three levels look empty. Also, if the removed level looks non-empty after CAS, we try to change it back quick before anyone notices our mistake! (This trick works pretty well because this method will practically never make mistakes unless current thread stalls immediately before first CAS, in which case it is very unlikely to stall again immediately afterwards, so will recover.)
We put up with all this rather than just let levels grow because otherwise, even a small map that has undergone a large number of insertions and removals will have a lot of levels, slowing down access more than would an occasional unwanted reduction.
大概意思就是,这个函数有犯个“小错”:把有index节点的index层给清除掉,但即使这样做了,也不会影响正确性,但会影响查找效率。
为了尽量不犯错,需要在前3个index层都存在的情况下,才会去降低head层。
但降低head层后,如果发现原head层其实有index节点,那么我们再设置回去,将功补过。
private void tryReduceLevel() {
HeadIndex<K,V> h = head;
HeadIndex<K,V> d;
HeadIndex<K,V> e;
if (h.level > 3 &&
(d = (HeadIndex<K,V>)h.down) != null &&
(e = (HeadIndex<K,V>)d.down) != null &&
e.right == null &&
d.right == null &&
h.right == null &&
//以上判断可知,前3层index层都存在
casHead(h, d) && // try to set
h.right != null) // recheck
casHead(d, h); // try to backout
}
返回情况
- 返回非null,说明一定是删除成功了,并返回了旧value。
- 返回了null。
- 没有找到想要删除的节点。(如果参数value是null,那么一定是这种情况)
- 找到了删除节点,但参数value和旧value不相等,所以不能执行删除动作。
marker存在的必要性
前面注释也说到了,marker之所以存在,是为了并发删除和插入能够正确的执行。不过直觉上来说,把node节点的value置为null,好像也足够了,甚至于说,对于b-->n-->f的结构,直接变成b-->f的结构不用置null好像还更方便。
先分析一下插入操作doPut,在执行b.casNext(n, z)时,虽然之前判断过b是没有被标记删除的(if (b.value == null || v == n) break;),但这个信息已经过时。
而删除过程的三个步骤在源码注释和doRemove都体现过,在此不赘述。
如果marker不存在
如果marker不存在,那么删除过程有两种方案:
- 先把node节点的value置为null,再断开node节点的前后连接。(这种方案看起来有点多此一举)
- 直接断开node节点的前后连接。
这两种方案其实没有本质区别,因为并发竞争的竞争点只在于修改node节点的后继,我们以后者为例分析。
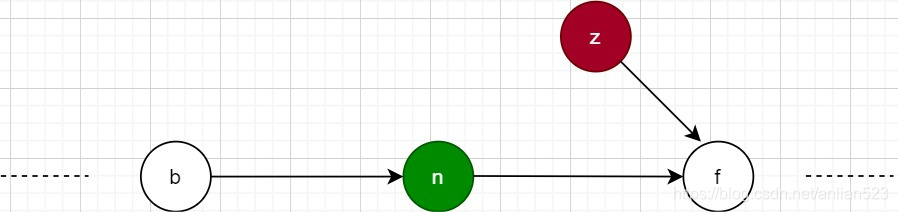
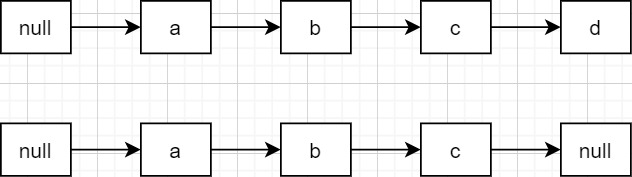
假设红色节点为新增节点,绿色节点为即将删除节点。现在:
- 插入操作认为,z的插入位置在n和f之间,而且插入操作之前已经判断过n不是删除节点了(虽然这已经过时了)。
- 删除操作认为,n在删除后,应该重新相连的两个节点是b和f。


如上两图可知,不管接下来 插入操作和删除操作谁先执行,最终都会导致z节点的消失,即从base层遍历不到z了。
marker存在时
| 删除线程 | 插入线程 |
|---|---|
| 插入操作已认为z的插入位置在n和f之间 | |
| n.value = null | |
| n.casNext(f, new markerNode(f)) | |
| b.casNext(f) |
现在的关键点在于,插入操作n.casNext(f, z)会穿插到上面执行顺序的哪两行之间去。
| 删除线程 | 插入线程 |
|---|---|
| 插入操作已认为z的插入位置在n和f之间 | |
n.casNext(f, z) | |
| n.value = null | |
| n.casNext(f, new markerNode(f)) | |
| b.casNext(f) |
如果上面这种顺序,删除线程第一步成功,但第二步失败(n.appendMarker(f)失败),因为b的后继不再是f了。此时删除线程会重新从head寻找删除节点(findNode),找到删除节点后会两次调用n.helpDelete(b, f)来完成删除操作(第一次完成上表第二步,第二次完成上表第三步)。
| 删除线程 | 插入线程 |
|---|---|
| 插入操作已认为z的插入位置在n和f之间 | |
| n.value = null | |
n.casNext(f, z) | |
| n.casNext(f, new markerNode(f)) | |
| b.casNext(f) |
如果上面这种顺序,分析同上。
| 删除线程 | 插入线程 |
|---|---|
| 插入操作已认为z的插入位置在n和f之间 | |
| n.value = null | |
| n.casNext(f, new markerNode(f)) | |
n.casNext(f, z) | |
| b.casNext(f) |
如果上面这种顺序,插入线程执行n.casNext(f, z)会失败,因为n的后继不再是f,而是一个marker。然后插入线程会重新从head寻找插入位置。
| 删除线程 | 插入线程 |
|---|---|
| 插入操作已认为z的插入位置在n和f之间 | |
| n.value = null | |
| n.casNext(f, new markerNode(f)) | |
| b.casNext(f) | |
n.casNext(f, z) |
如果上面这种顺序,分析同上,因为即使n和marker已经与链表断开链接了,n的后继还是那个marker,插入线程执行n.casNext(f, z)还是会失败。
经过以上分析可知,不管删除线程和插入线程的交叉执行顺序是什么,都不会产生错误的结果。
从本质上来说,因为删除过程的第一步是插入一个marker,这就把删除操作也变成了“插入操作”,自然作为“插入操作”的删除操作会和正常的插入操作会互斥,从而保证了并发删除和插入能有正常的结果。