文章目录
- 前言
- 核心成员
- 常用方法
- get
- set
- add
- remove
- remove(int index)
- remove(Object o)
- index >= len
- index < len
- findIndex代码块之后
- clear
- toArray
- 迭代器
- 总结
前言
CopyOnWriteArrayList 是一种写时复制的ArrayList,它将读操作和写操作的情形区分开来,并在写操作时拷贝原数组成员。
JUC框架 系列文章目录
核心成员
java"> /** 写操作时用来加锁 */
final transient ReentrantLock lock = new ReentrantLock();
/** 底层数组实现。注意volatile修饰在数组引用上 */
private transient volatile Object[] array;
/**
* 得到数组引用
*/
final Object[] getArray() {
return array;
}
/**
* 设置数组
*/
final void setArray(Object[] a) {
array = a;
}
/**
* 默认构造器。生成大小为0的数组
*/
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
- 在写操作时,ReentrantLock用来加锁。
- 数组引用是volatile的,保证了可见性。get/set方法的具体操作是return和赋值,所以这两个操作具有原子性。结合了可见性和原子性,所以get/set方法不需要CAS操作就可以保证在多线程环境下能正常工作。
- 最让人疑惑的是,为什么默认构造器中生成的数组大小为0。
array成员也不是final的,看来使用过程中,会不停对array成员赋值了。
常用方法
现在我们从CopyOnWriteArrayList提供的public方法入手,看看它是怎么做到Copy On Write的。
get
java"> private E get(Object[] a, int index) {
return (E) a[index];
}
public E get(int index) {
return get(getArray(), index);
}
get操作自然是一个读操作,所以全程都不用加锁。
set
java"> public E set(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
//获得原数组的引用
Object[] elements = getArray();
//获得对应索引的旧值
E oldValue = get(elements, index);
if (oldValue != element) { // 如果旧值与新值不是同一个对象
//生成一个新数组
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len);
//对应索引设置新值
newElements[index] = element;
//对数组成员赋值(重要)
setArray(newElements);
} else {
// Not quite a no-op; ensures volatile write semantics
setArray(elements);
}
return oldValue;
} finally {
lock.unlock();
}
}
set操作自然是一个写操作,所以需要加锁。具体过程是,复制出一个一模一样的新数组出来,然后将新数组对应索引设置为新值,最后把新数组赋值给array成员。
需要注意到,get操作是无锁的,set操作却是加锁的。也就是说,get操作可以在set操作过程中的任何时刻进行,具体的讲:
- 在set操作的
setArray(newElements)之前,执行了get操作的getArray(),那么get操作的是旧数组。 - 在set操作的
setArray(newElements)之后,执行了get操作的getArray(),那么get操作的是新数组。
看到这里,你已经发现了CopyOnWrite的秘密了,简单的说:无论有多少个读写操作在进行中,这些读写操作持有的数组引用最多可能是两个不同的数组,写操作因为加锁操作而互斥,所以新数组在一个时刻只可能产生一个,再算上旧数组——所以最多可能是两个不同的数组。
add
add也是写操作,需要加锁。
java"> public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//新数组大小比原数组大小 加1,但最后一个位置是空的
Object[] newElements = Arrays.copyOf(elements, len + 1);
//最后的空位置放新元素
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
逻辑简单,自己看吧。
java"> public void add(int index, E element) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
//原本索引范围0 - len-1,新的索引范围应为0 - len,所以下面这么检查
if (index > len || index < 0)
throw new IndexOutOfBoundsException("Index: "+index+
", Size: "+len);
Object[] newElements;
int numMoved = len - index;
if (numMoved == 0)//如果index刚好是len,说明一个元素都不用后移了
newElements = Arrays.copyOf(elements, len + 1);
else {//至少有一个元素需要后移
newElements = new Object[len + 1];
//先拷贝不用后移的元素
System.arraycopy(elements, 0, newElements, 0, index);
//再拷贝需要后移的元素
System.arraycopy(elements, index, newElements, index + 1,
numMoved);
}
newElements[index] = element;//设置新元素
setArray(newElements);
} finally {
lock.unlock();
}
}
这个版本的add可以将新元素插入到指定的位置。
remove
remove也是写操作,需要加锁。
remove(int index)
java"> public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index);//需要返回旧值
//删除前索引范围是0 - len-1,所以下面其实是len-1 - index
int numMoved = len - index - 1;
if (numMoved == 0)//如果index刚好是len-1,说明一个元素都不用前移了
setArray(Arrays.copyOf(elements, len - 1));
else {//至少有一个元素需要前移
Object[] newElements = new Object[len - 1];
//先复制不用前移的元素
System.arraycopy(elements, 0, newElements, 0, index);
//后复制需要前移的元素
System.arraycopy(elements, index + 1, newElements, index,
numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
这个版本用来删除指定索引上的元素。
remove(Object o)
java"> public boolean remove(Object o) {
Object[] snapshot = getArray();
int index = indexOf(o, snapshot, 0, snapshot.length);//如果元素存在,则返回一个有效索引
//如果索引无效,直接返回false
return (index < 0) ? false : remove(o, snapshot, index);
}
private boolean remove(Object o, Object[] snapshot, int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] current = getArray();
int len = current.length;
//如果数组成员已经改变,需要重新考察index的有效性,因为之后会根据这个index操作
if (snapshot != current) findIndex: {
//得到遍历范围最小值,这个范围不一定能找到元素,当元素被后移时
//注意index是索引,len是数组大小。
int prefix = Math.min(index, len);
for (int i = 0; i < prefix; i++) {
//严格的判断。只有当两个数组相同索引位置的元素不是同一个元素;
//且current索引元素和参数o 是equal的
if (current[i] != snapshot[i] && eq(o, current[i])) {
index = i;
break findIndex;//一旦判定成功,退出if分支
}
}
//如果index >= len,那么说明循环遍历了current每个元素都没有退出if分支
if (index >= len)
return false;
//接下来检查[index, len)范围内的元素
if (current[index] == o)
break findIndex;
index = indexOf(o, current, index, len);
if (index < 0)
return false;
}
Object[] newElements = new Object[len - 1];
System.arraycopy(current, 0, newElements, 0, index);
System.arraycopy(current, index + 1,
newElements, index,
len - index - 1);
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
这个版本用来删除指定对象。但由于调用私有方法后才开始加锁,所以可能私有方法时,数组成员已经改变。
注意java冒号的这种用法,用来退出代码块。
分析的重点在于if (snapshot != current) 内的内容。
可以分为两种情况:
- index >= len
- index < len
注意index是从snapshot里找来的索引,len则是current的大小。
index >= len
当index >= len时,for循环一定能遍历完所有的节点,如果遍历结束后都没有退出if分支,那么之后if (index >= len) return false;就一定会退出if分支。

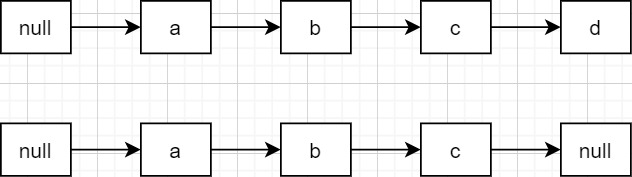
图例说明,D为indexOf找到的那个的元素。
上图例举了index = len的情况,可见这种情况可以确定current相比snapshot,元素减少了。如果index > len,那更是如此。也就是说int prefix = Math.min(index, len)肯定取到的是len,循环一定能够遍历到current的每个元素。但问题在于为什么要用if (current[i] != snapshot[i] && eq(o, current[i]))这么严格的判断,只使用这个判断的后者不行吗?
之所以这样,是因为最开始是通过indexOf(o, snapshot, 0, snapshot.length)算出来的index,这个indexOf的内部逻辑是通过equals判断的,现在indexOf得到的索引是3,那么说明前面的ABC既不是o本身,也不能通过o.equals判断相等。
现在既然已知了o不可能和snapshot前面的元素是同一个元素(==判断),所以if (current[i] != snapshot[i] && eq(o, current[i]))使用这么严格的判断也是合理的,显得更加严谨。
index < len
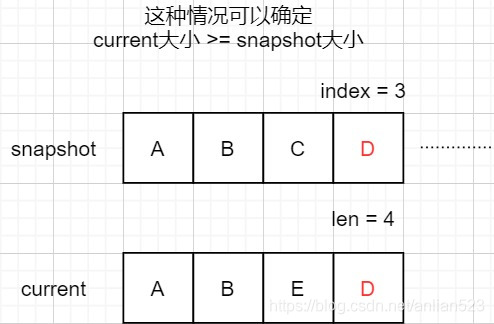
当index < len时,for循环不能遍历完所有的节点。现在prefix肯定是index了,至少for循环已经检查了[0,index)范围内的元素,但都还没有找到o。
所以接下来需要检查[index,len)范围内的元素(indexOf(o, current, index, len)),前面的if (current[index] == o) break findIndex;只是一种快速尝试,运气好的话,index索引刚好是o本身。
现在两种情况都分析完了,如果最后了发现index < 0,说明current里面没有o本身或能通过o.equals()判断的元素。
findIndex代码块之后
现在index已经被找到,执行相应操作
clear
clear也是写操作,需要加锁。
java"> public void clear() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
setArray(new Object[0]);//赋值为大小为0的元素
} finally {
lock.unlock();
}
}
toArray
谁也不知道你执行toArray后,会不会拿去写操作,所以这里还是得返回一个副本。
java"> public <T> T[] toArray(T a[]) {
Object[] elements = getArray();
int len = elements.length;
if (a.length < len)
return (T[]) Arrays.copyOf(elements, len, a.getClass());
else {
System.arraycopy(elements, 0, a, 0, len);
if (a.length > len)
a[len] = null;
return a;
}
}
迭代器
java"> public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
可以发现迭代器接受的是getArray(),即直接使用的CopyOnWriteArrayList的数组成员引用,看来这个迭代器想必是不支持写操作的了,只支持读操作了。因为读操作才是这样,不加锁,直接获取数组成员。
java"> static final class COWIterator<E> implements ListIterator<E> {
/** 保存引用 */
private final Object[] snapshot;
/** 游标,代表接下来要访问的元素索引 */
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
snapshot = elements;
}
public boolean hasNext() {
return cursor < snapshot.length;
}
public boolean hasPrevious() {
return cursor > 0;
}
@SuppressWarnings("unchecked")
public E next() {//读操作
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
@SuppressWarnings("unchecked")
public E previous() {//读操作
if (! hasPrevious())
throw new NoSuchElementException();
return (E) snapshot[--cursor];
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor-1;
}
public void remove() {//写操作不支持
throw new UnsupportedOperationException();
}
public void set(E e) {//写操作不支持
throw new UnsupportedOperationException();
}
public void add(E e) {//写操作不支持
throw new UnsupportedOperationException();
}
@Override
public void forEachRemaining(Consumer<? super E> action) {
Objects.requireNonNull(action);
Object[] elements = snapshot;
final int size = elements.length;
for (int i = cursor; i < size; i++) {
@SuppressWarnings("unchecked") E e = (E) elements[i];
action.accept(e);
}
cursor = size;
}
}
总结
- volatile + return操作/赋值操作,保证了数组成员的可见性和原子性。
- 读操作不用加锁,直接获取数组成员。
- 写操作需要加锁,并拷贝原数组成员。
优点:
- 保留了读操作的高性能。
- 避免了并发修改抛出的ConcurrentModificationException异常。
缺点:
- 写操作太多时,将产生高内存消耗。因为需要拷贝出新数组。
- 读操作不能保证看到最新的数据,即使写操作已经开始执行了。因为直到写操作执行
setArray之前,读操作都无法看到最新数据。
场景:
- 读操作多,写操作少的场景。
- 读操作允许看到非最新数据的场景。